






مشکلات مربوط به توسعه و ارائه خدمات رایانامه بومی به پنج گروه مشکلات مقیاس پذیری، پایداری سیستم، پشتیبانی، امنیت و حکومت طبقه بندی می شوند که عبارتند از:
1.1.3 مشکلات مقیاس پذیری
1. طراحی سیستم مقیاس پذیر برای پاسخگویی به کاربران بالا
برای طراحی چنین سیستمی دو مدل معمولا پیاده سازی می شود. برخی بخشها سعی می کنند به کمک سخت افزار مشکل تعداد کاربران بالا را رفع کنند ولی عملا بدلیل رشد غیر خطی سخت افزار های مورد نیاز و بالا بودن هزینه های سخت افزاری عملا امکان پذیر نیست علاوه بر آن معمولا عمر سخت افزار ها محدود است. و احتمال خرابی سخت افزار ها هست و مشکل single point of fail در این حالت بسیار بالا می رود.
معمولا سعی می شود با طراحی نرم افزار های مقیاس پذیر سعی شود که با افزایش تعداد سختافزارهای معمولی و اتصال ان ها به یکدیگر نیاز نرم افزار ها را برطرف نمود معمولا نرم افزار ها به صورتی طراحی می شوند که با سخت افزار های در کلاس PC و افزایش تعداد سخت افزارها متناظر به افزایش تعداد کاربران به صورت خطی این مشکل قابل حل است.
در جدول زیر مقایسه بین هزینه های سخت افزاری در دو مدل با یکدیگر مقایسه شده است. همان طور که مشاهده می شود با هزینه بسیار پایین تر مقدار CPU و RAM بسیار بهتری بدست می اوریم. بنابر این استفاده از سخت افزار های با ظرفیت بالا عملا در شبکه های مقیاس پذیر صرفه اقتصادی ندارد.
|
Typical x86 - based server |
Custom built x86 - based server |
||
|
PROCESSORS |
8 2-GHz Xeon CPUs |
176 2-GHz Xeon CPUs |
22x |
|
RAM |
64 Gbytes of RAM |
176 Gbytes of RAM |
3x |
|
DISK SPACE |
8 Tbytes of disk space |
7 Tbytes of disk space |
-1 TB |
|
PRICE |
$758,000 |
$278,000 |
$480,000 |
از طرفی استفاده از نرم افزار برای حل مشکلات مقیاس پذیری مشکلات زیادی دارد در ادامه به این موارد میپردازیم.
افزایش تعداد سخت افزار ها با عمر محدود احتمال خرابی را بسیار بالا می برد. مثال اگر ما 10000 PC با عمر 1000 روز داشته باشیم، هر روز با مشکل پیدا کردن 10 سیستم مواجه خواهیم شد. لذا نرم افزار طراحی شده بایستی در برابر خرابی مقاوم باشد و در صورت پیدا شدن مشکل سخت افزاری در تعدادی از سیستم ها سریعا امکان جایگزینی وجود داشته باشد و سیستم مختل نشود.
افزایش تعداد سخت افزار ها با کیفیت کمتر نیاز به فضای بیشتری دارد و هزینه های نگهداری، پشتیبانی و سیستم های سرد کننده را افزایش خواهد داد. لذا نیاز است مراکز داده با ظرفیت بالا طراحی شود.
ارتباطات زیاد بین سخت افزار ها از طریق شبکه انجام می شود لذا چنین زیر ساختی بایستی پهنای باند بین سرور ها به صورت مناسبی در نظر گرفته شود.
در نرم افزار ایمیل بیشترین بخش که نیاز است با افزایش تعداد کاربر رشد نماید، سیستم های نگهداری متا دیتای مربوط به ایمیل ها و سیستم های ذخیره سازی توزیع شده است. نرم افزار ایمیل نیازمند بخش های زیادی است که تمامی انها بایستی به صورت مقیاس بالا طراحی شود.
2. استفاده از Database مقیاس پذیر برای نگهداری Metadata
یکی از بخش های نرم افزار که بایستی مقیاس بالا را پشتیبانی نماید پایگاه داده است. پایگاه داده در ایمیل برای نگهداری اطلاعات ایمیل ها مانند گیرنده فرستنده و header ایمیل استفاده می شود. همچنین برای قابلیت search نیاز است مواردی از پایگاه داده index شود در حال حاضر در کد ایمیل به join و استفاده از transaction های ASID نیاز داریم. با توجه به قوانین CAB داشتن پایگاه داده که هم بتواند پایداری و قابلیت اطمینان را بدست اورد غیر ممکن است. ولی در دنیا شرکت هایی وجود دارد که با استفاده از newsql توانسته اند به پایداری 99.99999% بدون از دست دادن مسئله پایداری برسند.
با توجه به جدید بودن این حوزه پایگاه داده متن باز تجاری در این مورد وجود ندارد و تجربه کمی در استفاده از پایگاه داده ها وجود دارد.
3. ایجاد مقیاس پذیری در دیتابیس به صورت پایدار
برای حل مسئله پایداری، پایگاه داده هایی مانند nuodb[1] و یا cockroachdb وجود دارند. ولی مشکلاتی از قبیل تجربه پایین استفاده از این پایگاه و یا متن باز بودن وجود دارد لذا مشکل اساسی در پیاده سازی پایگاه داده های مربوط به ایمیل هست.
ضعف تجربه و دانش پیشین در کشور برای ارائه خدمات «امن»، «مقیاس پذیر» و «رضایت بخش» به مردم با توجه به نبودن زیر ساخت ها و شرکت های پشتیبانی کننده از این نوع پایگاه داده ها و نرم افزار ها است.
4. سیستم فایل مقیاس پذیر
سیستم فایل های مقیاس پذیر زیادی وجود داراد که برخی از انها در جدول زیر امده است:
|
Site |
|
|
HDFS |
|
|
coda |
|
|
openafs |
|
|
QFS |
|
|
Xtreemfs |
|
|
Kosmosfs |
|
|
gluster |
|
|
ceph |
|
|
ori |
|
|
Moosefs |
|
|
mogilefs |
|
|
|
The Lustre |
|
https://github.com/discoproject/disco/blob/master/doc/howto/ddfs.rst |
disco |
|
gridgain |
|
|
seaweedfs |
|
|
9P(bellabs) |
|
|
Fhgfs beegfs |
|
|
tahoe-lafs |
|
|
PlasmaFS |
|
|
weed-fs |
|
|
Chirp |
|
|
tachyon |
|
|
slash2 |
این سیستم ها دارای ویژگی های متفاوتی است که ما سعی کردیم انها را بایکدیگر مقایسه نماییم تا ببینیم کدام سیستم می تواند مشکلات ما را در زمینه سیستم فایل مورد نیاز برای نگهداری اتچمنت ها رفع نماید.
کارهای کلی این پروژه به صورت زیر است.
1) نصب و تستی برای owncloud بدون Replication برای owncloud
2) تغییر کد های owncloud برای کارکردن با سیستم فایل مورد نظر
3) راه میرور با دو نود
4) تست سرعت و کارایی
5) راه اندازی و بهبود سرعت با استفاده از reed selemon
6) رفع باگ ها احتمالی در سیستم
7) عملیاتی کردن بر روی النون برای owncloud
نصب
در این فاز QFS و HDFS بر روی سرور ها نصب می شود و برای اتصال owncloud به این سرور کد owncloud تغییرات جزئی پیدا می کند تا برخی از این مشکلات حل شود تا بتوان تست ها مربوط به کارایی و replication را گرفت.
تست وضعیت replication و وضعیت میرور
در این بخش سعی می شود با دو نود دیتا در دو دیتاسنتر میرور تست شود و وضعیت و خطاهای هر کدام برای سناریو های زیر مشخص گردد.
1) وضعیت replication و خطایی که در write ایجاد می کند:
بر اساس replication policy که تعریف یا انتخاب می شود ممکن است خطاهایی اتفاق بیفتد. برای ایجاد قابلیت تحمل خطا برای read/write باید از WqRq یا WaRa استفاده کرد. یک خطای رایج استفاده از WqRq همراه با 2 replica است که وقتی یکی دچار خطا می شود نمی تواند خطا را تحمل کنید و حداقل باید 3 replica موجود باشد.
خطای دیگر این است که اگر replication mode به صورت Read-Only تعریف شده باشد نمی توان هیچ تغییری از جمله Write ایجاد کرد و گرنه خطا ایجاد می شود.
2) وضعیت خطاهایی که در read انجام می شود:
در بعضی موارد وقتی policy را آپدیت کنیم و بخواهیم نحوه دسترسی را تغییر دهیم پس از آن با error مواجه می شویم.
3) تاخیر در read :
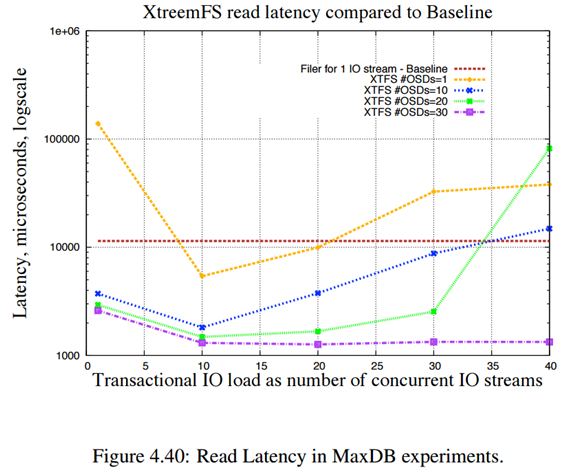
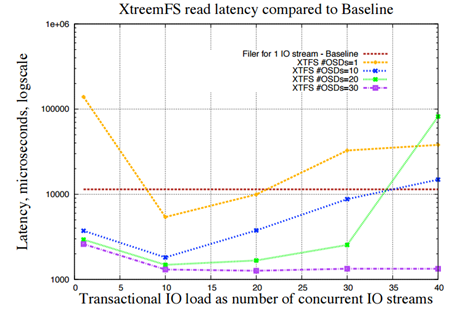
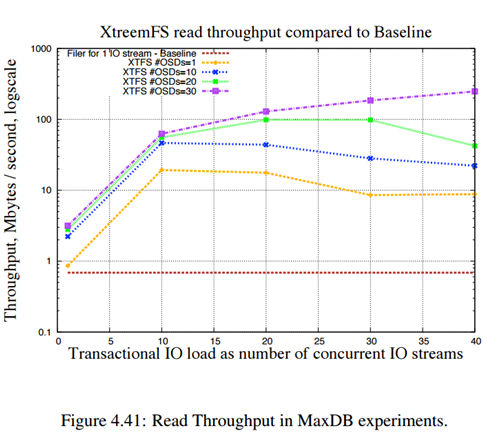
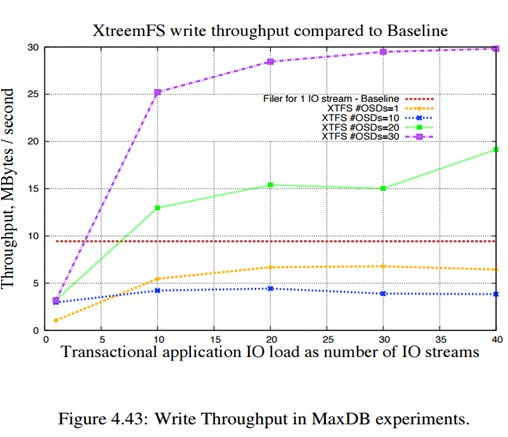
همان طور که در شکل که مربوط به یک آزمایش انجام شده است مشاهده می شود ، نمودار تاخیر در read بر حسب تعداد عملیات های IO هم زمان که در این جا همان عملیات reading است نشان داده شده است. هر رنگ مربوط به سیستم Xtreemfs با تعداد OSD(Object Storage Device) مخصوص به خود است. ضمن این که OSD ها سرورهایی هستند که فایل ها را به صورت Object نگهداری میکنند و بر خلاف برخی فایل سیستم های دیگر که دیتاها را به صورت block و sector نگهداری می کنند. در واقع وقتی به صورت توزیع شده Xtreem را نصب می کنیم یکی از 3 سروری که حتما باید ایجاد شود همان OSD است که مربوط به Storage می باشد (در کنار 2 سرور directory و metadata).
همان طور که دیده می شود هر چه تعداد OSD ها بیشتر باشد با افزایش عملیات IO افزایش تاخیر بسیار کمتر و بهینه است، طوری که برای تعداد 30 OSD بین 10 تا 40 عملیات اختلاف تاخیر در read تقریبا صفر است. ضمن این که برخی قسمت هایی که افزایش ناگهانی مشاهده می شود به دلیل بار موجود در شبکه (network load) است که نشان می دهد xtreemfs به این فاکتور وابسته است.
4) وضعیت سیستم در زمان قطع یکی از نود ها:
این سئوال برای هر دو عمل read و write در قسمت های بعد پاسخ داده شده است.
5) وضعیت سیستم در حالت برگشت یکی از نود ها
6) وضعیت سیستم در هنگام قطع یکی از نودها در read
برای این مورد یک فایل ویدیویی نسبتا کوچک را شروع به اجرا شدن (خواندن) خواهیم کرد و سپس یکی از OSD ها را stop می نماییم که بعد از چند ثانیه تاخیر و توقف ویدیو دوباره شروع به اجرا شدن می کند. برای این که در این حالت مشکلی پیش نیاید حداقل باید 3 OSD وجود داشته باشد.
در اینجا 4 مرحله اتفاق می افتد:
1- بعد از انتخاب شدن primary جدید، اطمینان پیدا می کند که ورژن چانک هایش به روز است.
2- سپس از بقیه سرورهای بک آپ درخواست می کند تا چانک هایشان را همراه با ورژن آن ها برایش ارسال کنند.
3- سپس primary چانک های دریافت شده را merge می کند. و اگر دید چانکی مورد نیاز است و موجود نیست آن را از بقیه backup ها دانلود می کند.
4- بعد از انجام این مراحل می تواند ادامه سرویس دهی را به عنوان primary به کلاینت انجام دهد.
7) وضعیت سیستم در هنگام قطع سیستم در هنگام write:
وقتی هنگام write یک node قطع می شود 5 مرحله طی می شود تا سیستم دچار مشکل نشود.
1- در مرحله اول کلاینت با گرفتن لیست storage server ها به صورت random یکی را انتخاب می کند.
2- سپس storage server انتخاب شده برای آن فایل primary می شود و اطلاعات آخرین وضعیت آن فایل را از سایرین گرفته و ترکیب می کند.
3- حالا کلاینت می تواند عملیات های مورد نظر را روی فایل انجام دهد.
4- با انجام عملیات write، primary server بقیه را هم update می کند تا backup موجود باشد.
5- وقتی primary قطع شد کلاینت به یک سرور دیگر وصل شده و سرورها یکی از بین خودشان را به عنوان primary انتخاب می کنند و مرحله 2 تکرار می شود. در این وضعیت کاربرها اروری مشاهده نمی کنند و فقط با مقداری تاخیر در انجام عملیات رو به رو می شوند.
8) بررسی وضعیت سیستم در هنگام موارد مورد نیاز برای random access مانند download با دانلود منیجر ها:
در تنظیمات (Configuration) با کمک babudb.repl.chunkSize experimental, optional که یک عدد صحیح بزرگتر از صفر را به عنوان پارامتر می گیرد، فایل های دیتابیس را می توان به chunk هایی با این اندازه تقسیم کرد.
ضمن این که دستور دیگری وجود دارد که با کمک آن میتوان اندازه چانک ها را تغییر داد.xtfsutil --set-dsp –s 32 –w 1 باعث می شود اندازه چانک ها به 32kb تغییر کند.
برای بررسی جزئی تر این موارد می توان به لینک زیر مراجعه کرد و با جستجوی همین دستورات به قسمت مورد نظر رسید:
http://www.xtreemfs.org/xtfs-guide-1.2.pdf
تست سرعت و کارایی
هدف از این بخش بهبود فرایند میرور و کارایی این زیر ساخت برای تعدیل تاخیر بوجود امده در اثر استفاده از سیستم توزیع شده است. و همچنین بهبود overhead نگهداری داده به صورت backup و میرور است. در این بخش دو حالت الگوریتم معمولی و reed Solomon بررسی ها صورت می گیرد.
بررسی سرعت و کارایی برای حالت میرور 3 در سه مرکز داده
در جدول زیر معیار های سرعت و کارایی امده است. هدف از مقایسه پر کردن جدولی است که دارای ستون های زیر باشد:
- نام پگیج
- قابلیت پیشتیبانی از geo
- تاخیر در write داده در حالت عادی
- تاخیر در write داده در حالتی fail بر خی از نود ها
- تاخیر در read داده در حالت عادی
- تاخیر در read داده در حالتی fail بر خی از نود ها
- مشکلات احتمالی در write (در لحظه fail شدن نود ، در لحظه recovery)
- مشکلات احتمالی در read (در لحظه fail شدن نود ، در لحظه recovery)
- مقدار پهنای باند اضافه مصرف شده برای read
- مقدار پهنای باند اضافه مصرف شده برای write
- مقدار فضای اضافه اشغال شده بر روی دیسک
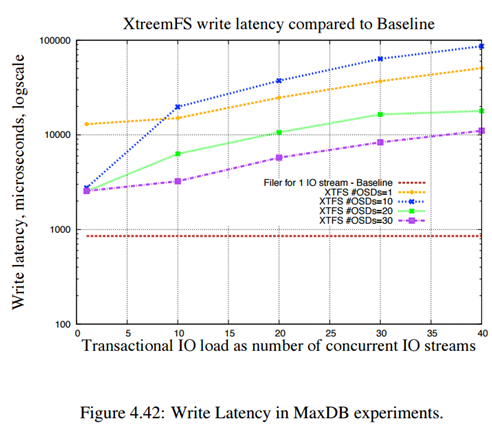
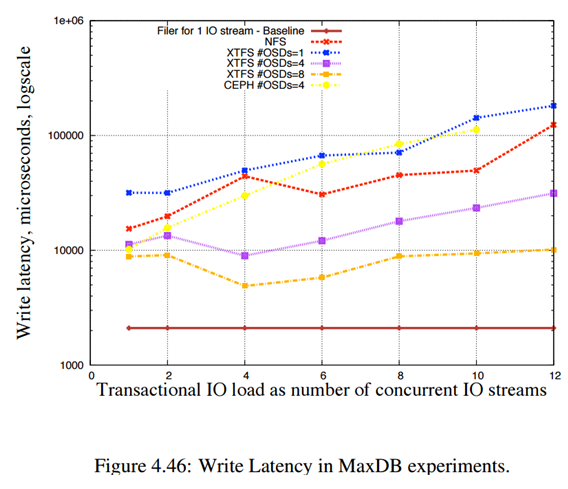


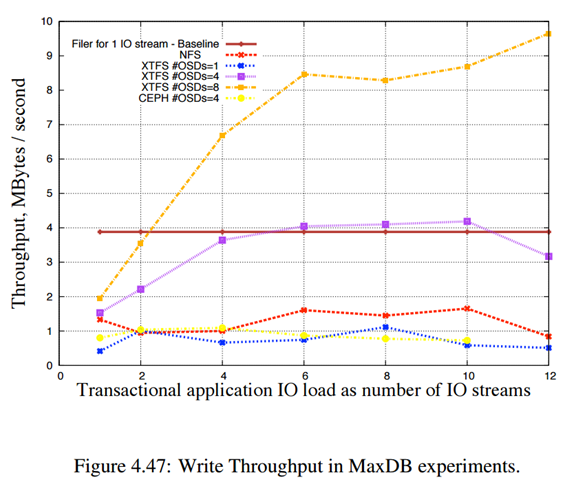
توجه شود تمامی موارد بالا برای fail 3 در سه مرکز داده بررسی می شود.
این موارد برای سیستم فایل های زیر بررسی می گردد.
1) بررسی و مقایسه QFS ، HDFS (در دو حالت NFS و HFTP)
2) سعی در نوشتن داده ها در حالت های reed Solomon ، geo replication مروبط به GlusterFS
باتوجه به بررسی های صورت گرفته، Xtreemfs قابلیت Reed-Solomon ندارد (بر خلاف GlusterFS).
3) از لحاظ سرعت و overhead
بررسی سرعت و کارایی در حالت دو نود در دو مرکز داده
در این حالت تمامی موارد بخش قبل برای دو نود در دو مرکز داده مقایسه می گردد.
بررسی replication بقیه موارد مورد نیاز
در این بخش سعی می شود بقیه بخش های سیستم که به سیستم فایل مربوط به مانند name node و داده های پایگاه داده بررسی شود.
بین name node ها
هدف از این بخش راه اندازی مکانیسمی برای replication ، master—master بین name نود است. تمامی مشکلات احتمالی در این بررسی بایستی در نظر گرفته شود؛ ابتدا به صورت master--- slave پیاده سازی صورت می گیرد سپس داده ها به صورت master – master انجام می شود.
5. کمبود خدمات رایانش ابری مقیاس پذیر
از انجایی که مسئله مقیاس پذیری بالا یکی از مسائل مشکل است و گاهی پروژه ای در حد ایمیل است، بسیاری از شرکت ها توانسته اند مشکل خود را از طریق سرویس های ابری شبکه ای حل نمایند. ولی متاسفانه در این زمینه شرکت داخلی که نیاز های ما را بتواند پاسخ گو باشد وجود ندارد که مجبور خواهیم شد این مسئله را در داخل شرکت حل نماییم.
2.1.3 مشکلات پایداری سیستم
1. کمبود شدید نیروهای متخصص و باتجربه به منظور پیاده سازی سیستم پایدار 7×24
یکی از نیاز های سیستم، ایجاد سازکار برای فرایند های پشتیبانی تمام وقت از سیستم است. درخواست های زیادی برای سیستم عمومی وجود دارد و ارتباط با مشتریان از کانال مشخصی صورت نمی گیرد. معمولا مشتریان پیگیری زیادی برای مشکل ندارند و معمولا به سرویس های مشابه در صورت ناراضی بودن مراجعه می نمایند؛ لذا راه اندازی سیستم یکپارچه جهت پشتیبانی و ایجاد ساختار های کارا جهت پشتیبانی یک امر ضروری است.
در این زمینه استاندارد های مختلفی مانند ITIL وجود دارد که با توجه به SLA یک سرویس اقدام به طراحی تیم برای پشتیبانی می نماید. از انجایی که در کشور ما سرویس های عمومی رایگان زیادی وجود ندارد و مردم در زمینه پشتیبانی این سرویس ها اموزش های کافی ندیده اند، تجربه و تخصص کافی هم در سمت مشتریان و هم در سمت متخصصان شرکت وجود ندارد. اولویت بندی درخواست ها و پاسخ به موقع یکی از موارد مهم است که تاثیر قابل توجهی در استفاده کاربران از سیستم دارد.
2. ایجاد سامانه مانیتورینگ پایدار به منظور کشف failover ها و راه اندازی مجدد سرورها
سامانه ایمیل الکترونیک بومی نیازمند سیستم مانیتورینگ امنیت و مدیریت متمرکز رخدادها است. برای این منظور نیاز به راه اندازی سامانه راه اندازی مانیتورینگ امنیت می باشد.
در سیستم ایمیل بومی النون از تکنولوژی ها و سرویس هایی که در جدول زیر امده است استفاده شده است. هدف از این پروژه راه اندازی سامانه ای است که تمامی لاگ های ایجاد شده در این سرویس ها را در خود ذخیره نماید.
جدول۴: لاگ های موجود در سیستم و خلاصه از اطلاعات موجود در آن
|
تکنولوژی |
اطلاعات مهم موجود در log |
اهمیت |
سادگی |
نوع سرویس |
|
ESX |
وضعیت سخت افزار سرور شرایط محیطی و هارد |
متوسط |
ابزار استاندارد ولی دسترسی سخت |
3-2 |
|
CentOS |
تلاش برای ورود به سیستم، خطاها دسترسی و لاگ های مربوط به فایروال iptable |
متوسط |
ابزار استاندارد |
3-2 |
|
Apache |
لاگ های دسترسی کاربران به صفحات ، ip و تعداد مراجعات به صفحه |
کم |
ابزار استاندارد |
3-1 |
|
spamassassin |
اطلاعات ایمیل های ورودی که spam شده اند. |
مهم |
ابزار استاندارد |
3-2 |
|
webapp |
اطلاعات json و درخواست های کاربر |
متوسط |
تولید شده توسط تیم تحلیل سخت |
3-3 |
|
ECP |
نحوه اتصال کاربران خطاهای اتصال ، کنترل دسترسی کاربران تلاش ها برای ورود به ایمیل |
مهم |
تولید شده توسط تیم تحلیل سخت |
3-2 |
|
Sms Engine |
Smsهای ارسالی و دریافتی. Sms هایی که به کاربران رسیده است. وضعیت اتصال خط پیامک |
مهم |
تولید شده توسط تیم تحلیل سخت |
3-2 |
|
Pfsense |
اطلاعات ترافیک مصرفی، وضعیت لینک ها و بسته های drop شده. لاگ های مربوط به snort و WAF |
متوسط |
ابزار استاندارد |
3-1 |
|
postfix |
تعداد و حجم ایمیل های ارسالی و دریافتی و وضعیت رسیدن یا spam شدن انها |
مهم |
ابزار استاندارد |
3-1 |
|
Clamav |
تعداد فایل های ویروسی، |
کم |
ابزار استاندارد |
3-2 |
|
درایو(owncload |
فایل های به اشتراک گذاشته شده |
کم |
تولید شده توسط تیم تحلیل سخت |
3-3 |
|
LDAP |
اطلاعات تصدیق اصالت و وصل شدن کاربران به سرور ایمیل |
مهم |
ابزار استاندارد |
3-1 |
|
mysql |
اطلاعات اتصال به پایگاه داده و حجم رکورد های بازیابی شده. |
کم |
ابزار استاندارد |
3-2 |
|
اسکریپت backup |
وضعیت نسخه های پشتیبان سرور |
مهم |
تولید شده توسط تیم تحلیل سخت |
3-3 |
|
اسکریپت های میرر |
وضعیت داده های ارسالی به سرور های میرور و تبادل داده بین سرور اصلی و میرور |
مهم |
تولید شده توسط تیم تحلیل سخت |
3-3 |
گزارش گیری
سیستم بایستی قادر باشد گزارشات را بر حسب زمان های ماهانه، روزانه، ساعت، سالیانه ارائه نماید. و در هر گزارش 10 نفر برتر را اعلام نماید. تمامی گزارشات بایستی داینامیک و بر حسب نیاز اپراتور قابل تعیین باشد. همچنین بایستی قابلیت correlate ، رویدادها و ساختن رویداد های انها بر اساس ترکیب لاگ های سامانه های مختلف وجود داشته باشد و امکان تعریف نمودار ، چارت بر اساس اطلاعات مورد نیاز کاربر نیز وجود داشته باشد.
به عنوان مثال برای لاگ مربوط به spam کاربر بتواند گزارش زیر را در سامانه مشاهده نماید.
- درصد ایمیل دریافتی spam شده از کل ایمیل های دریافتی در 3 ساعت اخیر
- درصد ایمیل ارسال spam شده از کل ایمیل های ارسالی در 3 ساعت اخیر
- ده نفر اول که در سه ساعت اخیر بیشترین spam را دریافت کردند
- ده نفر اول که در سه ساعت اخیر بیشتری spam را ارسال کردند.
- ده ip اول که بیشرین spam را در سه ساعت اخیر دریافت کردند.
- ده ip اول که بیشتری spam را در سه ساعت اخیر ارسال کردند.
اطلاع رسانی
اپراتور سیستم بایستی بتواند حالاتی را تعریف نماید که در ان حالات، اتفاقات سیستم به صورت sms و ایمیل برای کاربران مشخص شده ارسال شود. برای ارسال sms از smsengine و برای ارسال ایمیل نیز از سرویس ایمیل النون استفاده نماید.
برای مثال اپراتور بایستی بتواند برای بحث spam موارد زیر را تعریف نماید:
اگر تعداد spam های ارسالی بیشتر از 90 در صد ایمیل ها در بازه 5 ساعته شد و حجم log مربوط به ایمیل های ارسالی بیشتر از 50% هارد سیستم بود sms ارسال شود.
برای راه اندازی این سیستم از موتور سامانه متن باز OSSIM[2] استفاده می شود و قابلیت های مورد نیاز به صورت پلاگین به ان متصل خواهد شد. همچنین می توان از ابزاهایی که در ادامه ذکر می شود بهره برد.
جدول ۵ـ لیست ابزاهای پیشنهادی
|
مانیتورینگ |
|
|
مانیتور کردن بالا بودن سرویس ها |
|
|
برای انالیز ترافیک و کاری که سرویس انجام می دهد |
|
|
بر روی pfsense نصب شده است. برای تحلیل پرتکل و نوع ترافیک مبادله شده بین سرویس ها و کاربران |
|
|
برای اطلاعات session |
|
|
برای تولید Netflow از ترافیک |
|
|
برای جمع اوری و انالیز اطلاعات Netflow ها |
|
|
سیستم های تشخیص نفوذ |
|
|
تشخیص mac حمله کننده |
|
|
برای تشخیص نفوذ به سرویس ها |
|
|
برای scan اسیب پذیری های سیستم و استفاده از ان در corolation |
|
|
سیستم تشخیص نفوذ |
|
|
سیستم تشخیص نفوذ می تواند برای cross correlation با openvas ترکیب شود |
|
|
یک سیستم تشخیص نفوذ host base |
|
|
شامل برخی ابزارهای بالا برای مانیتورینگ امنیت |
|
1- نصب ابزاها با پلاگین های موجود در اینترنت برای OSSIM برای تعدادی از سرویس ها که امکان اتصال انها وجود دارد.
2- تولید پلاگین ها برای ابزارهایی که log استاندارد تولید می کنند.
3- تولید پلاگین های تحلیل log برای سیستم هایی که خاص سرویس ایمیل النون است.
3. کمبود مراکز داده پایدار، ایمن و پاسخگو
در پروژه ایمیل از مرکز داده های مختلفی استفاده شد است از جمله این مراکز می توان به تبیان، سروش رسانه، پارس انلاین، افرانت و زیر ساخت اشاره کرد.
متاسفانه مراکز داده معمولا SLA که مناسب سرویس ایمیل باشد ارائه نمی دهند. بدیهی است SLA سرویس ما پایین تر از مراکز داده خواهد بود اگر بخواهیم از یک مرکز داده استفاده کنیم. مشکلاتی از قبیل دیده نشده از برخی رنج های IP ، قطعی سرویس مشکلات برق و سخت افزاری امری اجتناب ناپذیر در مراکز داده است. پشتیبانی و پاسخ گویی تیم مرکز داده، تاثیر مستقیم در کیفیت سرویس ایمیل دارد. در استفاده از ایمیل در بسیاری از مواقع مشکلات ناشی از ضعف پشتیبانی مراکز داده باعث از دسترس خارج شدن سرویس های ما شده است.
3.1.3 مشکلات پشتیبانی
1. توسعه سیستم های دقیق پشتیبان گیری در معماری با مقیاس بالا
نگهداری حجم بالای پشتیبان ها در مراکز داده مختلف نیازمند فعالیت های زیادی است. بسیاری از مشکلات کنترل ریسک و هزینه است به گونه ای که با هزینه معقول بتوانیم در شرایط بحرانی اطلاعات کاربران را درکمترین زمان ممکن بازیابی نماییم.
2. کمبود نیروی انسانی متخصص جهت پشتیبانی و پاسخگویی به صورت 7*24
3. کاهش incident ها از طریق root cause کردن مشکلات
4. افزایش رضایت مشتریان و کاربران با توجه به متدولوژی مدیریت خدمات اخذ شده
4.1.3 مشکلات امنیت
1. امنیت و جلوگیری از حمله شدن به ایمیل و spamer ها
سرویس های ایمیل یکی از اهداف بات ها و حمله هکر ها است. بسیاری از شبکه های بات ها سعی می کنند با دسترسی به سرویس ایمیل اقدام به ارسال ایمیل با تعداد بالا نمایند. در سیستم ایمیل النون ما مواجه با حجم عظیمی که حملات به سرور های ایمیل گیتوی هستیم. این حملات در طی زمان به روز می شوند و سعی می کنند اسیب پذیری های جدیدی را در سیستم ها برای حملات پیدا کنند؛ لذا پویش مستمر امنیت و به روز رسانی سرویس های انتی spam و انتی ویروس و سیستم امنیتی یکی از مشکلات ایمیل است. بسیاری از اوقات این سیستم ها به دلیل سخت گیری هایی که انجام می دهند ممکن است باعث ایجاد false positive شوند و باعث نارضایتی کاربران گردند.
- برخی از سرو های ایمیل توسط ویروس ها و bot ها الوده می شود و به عنوان سرور های ارسال spam استفاده می شود. این روش بسیار معمول است و متاسفانه بررسی mailq به کشف این حمله کمک نمی کند زیرا مورد غیر عادی مشاهده نمی شود. بررسی ترافیک شبکه می تواند به یافتن این حملات کمک نماید. برای مقابله با این نوع حمله موارد زیر پیشنهاد می شود:
- استفاده از انتی ویروس قوی بر روی سرور ها
- به روز رسانی امنیتی و نصب وصله های امنیتی بر روی سرور ها
- بستن پورت 25 به بیرون برای سرور هایی که نیاز به این پرت ندارد.
- رعایت اصل حداقل دسترسی در مورد شبکه و دسترسی کاربران.
- نصب مجدد و پاک کردن کامل سیستم عامل هایی که الوده شده اند.
- جدا کردن شبکه سیستم هایی که ریسک بالایی دارند.
- حمله کننده کلمه عبور و نام کاربری یکی از کاربران سیستم را در می اورد و از ان ها برای ارسال spam استفاده می کند.(در مورد سیستم gateway که برای اتصال با استفاده از imap و smtp دارد، استفاده می کند):
- استفاده از کلمات عبور قوی برای کاربران
- در مورادی که کاربر sla پر نکرده یا اینکه کلمه عبور ضعیف است نتواند وارد سیستم شود.
- نام کاربری های عمومی مانند info و admin کلمات عبور سخت داشته باشند و به کاربران واگذار نشوند.
- کلمات عبور به صورت دوره های شش ماهه این تغییر نماید.
- تعداد ایمیل های دریافتی و ارسالی کنترل شود و در صورت مشاهده رشد غیر عادی گزارش گردد.
- تعداد ایمیل های ارسالی و دریافتی برای کاربران محدود شود.
- سیستم های کاربران از جهت الودگی به ویروس و تروجان بررسی گردد.
- در صورت بروز این مشکل بلافاصله نام کاربری که حمله کننده اطلاعات ان را سرقت کرده شناسایی و کلمه عبور تغییر نماید.
- اشتباه در تنظیمات شبکه
- در موارد بسیار فراموش کردن در مورد نحوه تنظیمات ممکن است باعث شود حمله کننده بتواند حملاتی را انجام دهد؛ برای حل این مشکل بایستی بعد از تغییر و یا انجام تغییرات شبکه این موارد بازبینی گردد.
2. پشتیبانی و امن سازی imap , pop3
یکی از سرویس های که معمولا هدف حملات قرار می گیرند imap و pop3 است. در این سرویس ها سعی می گردد با به روز رسانی این سرویس ها و فعال سازی رمزنگاری، بر این مشکلات غلبه شود؛ ولی از انجایی که برای دسترسی در این سیستم ها از درگاه های مختلف استفاده می شود و کنترل انها مشکل است (زیرا انعطاف و تغییر این پرتکل ها بسیار دشوار است و معمولا کلاینت هایی که از سیستم ها استفاده می کنند)، نمی توانند محدودیت های زیادی را بپذیرند.
3. جلوگیری از مشکلات مربوط به brutreforce نام کاربری و کلمه عبور
یکی از حملاتی که به سیستم ایمیل انجام می شود حدس زدن نام کاربری و کلمه عبور با امتحان کردن تعداد زیادی از حالات ممکن است. برای جلوگیری از این حملات سیاست های مختلفی از جمله captcha و یا بستن ip در نظر گرفته شده است. همچنین سعی شده در انتخاب کلمات عبور موارد زیر رعایت شود.
قوانین زیر در نگهداری و تغییر کلمات عبور در کل سیستم ایمیل بومی رعایت می شود:
1) کلیه کلمات عبور پشتیبانی بایستی بیشتر از 12 حرف شامل حرف و کارکتر خاص باشد.
2) بایستی به هیچ وجه کلمات عبور email بر روی اینترنت منتقل نشود.
3) به صورت کلامی با صدای بلند گفته نشود.
4) برای هر کاربر یک user مجزا و با حداقل دسترسی در نظر گرفته می شود.
5) کاربر root تغییر نام داده می شود و nologin می شود و کلمه عبور تنها در اختیار admin ها است.
6) برای نرم افزارها نیز در صورت نیاز کلمه عبور تعریف می شود.
7) کلمه عبور ادمین های سرور هر ماه تغییر می کند.
8) کلمه عبور root در سه ماه یک بار تغییر می کند.
9) کلمه عبور مربوط به نرم افزارها (شامل کلمه عبور پایگاه داده) هر شش ماه یک بار تغییر می نماید.
ولی این اقدامات کافی نبوده و معمولا حمله کننده ها با استفاده از ضعف انتخاب نام کاربری برای کاربران و استفاده از imap برای brute force استفاده می کنند. استفاده از تعداد زیادی از کاربران از یک vpn مشکلاتی از قبیل false positive به وجود می اورد و سختی این سیاست ها یکی از مشکلات کنترل کلمات عبور است. به نظر می رسد استفاده از OTP و کلمات عبور دوعامله می تواند تا حد زیادی این مشکلات را بهبود ببخشد.
4. جلوگیری از حملات در سطح شبکه و سیستم عامل
در سطح شبکه و سیستم عامل سعی شده است سرویس ها به صورت مداوم بررسی شود و سیاست ها و چک لیست هایی برای به روز رسانی امنیتی و محدودیت استفاده از انها انجام شود.
سیاست محیط تست و توسعه
قوانین و سیاست های زیر در مورد ماشین های تست و محیط تست وجود دارد.
1) تا جای ممکن محیط تست بر روی سرورهای داخلی ایجاد می شود و در صورت کمبود منابع و ممکن نبود تست کارا، این امر بر روی سرور های عملیاتی انجام می شود.
2) ماشین های تست در vlan و شبکه جدا بر روی ESx و pfsense قرار می گیرند و به صورت شبکه ای تا جای ممکن دسترسی از سایر سرور ها قطع می شود.
3) پهنای باند اینترنت اختصاص داده شده برای ماشین تست به صورت shape شده محدود می شود.
4) تنها دسترسی از طریق تونل به ماشین های تست امکان پذیر است و تا جای ممکن دسترسی های شبکه ای محدود می شود.
وضعیت شبکه سرور های عملیاتی
قوانین زیر در مورد سرور عملیاتی رعایت می گردد.
1) سرور ها به تدریج در چهار شبکه مجزا قرار می گیرند (سرور های داده (ldap و mysql) سرور های وب، سرور های infra (zcp ،spam)، ایمیل gateway (postfix،gateway،()
2) سرور های وب در پشت waf قرار می گیرد. مخصوصا سرور های مربوط به wordpress
3) سرور ها به صورت هفتگی به روز رسانی می گردد (patch های امنیتی بر روی انها نصب می گردد).
4) ماژول مربوط به IDP فعال می گردد.
سیاست بررسی log ها و SOC
چک کردن دوره ای log های مربوطه و history مربوط به دستورات توسط SOC
5. جلوگیری از حملات در سطح نرم افزار و سرویسهای اختصاصی
برای تست نرم افزار به صورت دوره ای هر یک سال یکبار سیستم ها مطابق استاندارد های بین المللی تست می شود. برای تست نرم افزارها از استاندارد owasp، SANS و infosec استفاده می شود و برای تست شبکه از استاندارد OSSTM استفاده می گردد. هدف از تست های امنیتی یافتن و گزارش اسیب پذیری ها در تعامل با توسعه دهندگان سیستم است.
تمامی اطلاعات سیستم شامل کد نرم افزار در اختیار تست کننده قرار خواهد گرفت تا بیشترین اسیب پذیری های ممکن از سیستم یافت شود.
هدف اصلی رفع اسیب پذیری های امنیتی سیستم است و صرف یافتن اسیب پذیری اگرچه با ارزش است ولی هدف اصلی رفع اسیب پذیری ها است. لذا مجری تست موظف است راه حل های رفع اسیب پذیری را با جزئیات کامل ارائه دهد. همچنین تمامی فرایند تست یایستی در قالب سناریو همراه با عکس و فیلم مستند شود.
در مواردی که نیاز به توضیحات بیشتر در مورد سیستم است بایستی با برگزاری جلسات با توسعه دهنده موارد تست توضیح داده شود. توسعه دهنده با کمک مجری تست مسئول رفع اسیب پذیری ها است.
ورودی های تست
برای تست ابتدا جلسه شناخت سیستم شامل افراد شبکه، توسعه دهنده ها و تست کننده سیستم برگزار می شود و در این جلسه تمامی مستندات سیستم به مجری تست تحویل داده می شود. هدف از این جلسه اشنایی مجری تست با معماری و نحوه عملکرد سیستم است.
در طی فرایند تست نیز تست کننده با توسعه دهنده در ارتباط است و موارد تست را با توسعه دهنده هماهنگ و توضیحات لازم در اختیار توسعه دهنده قرار می گیرد.
خروجی تست
مجری تست موظف است خروجی های تست را در قالب OWASP گزارش نماید. هم سناریو های موفق و اسیب پذیر و هم نا موفق در گزارش خواهد امد. در طی انجام پروژه خروجی هر سناریو که تست می شود شامل عکس و فیلم و خلاصه از فعالیت ها به صورت گزارش مقدماتی ایمیل می شود. در پایان پروژه گزارش مفصل از وضعیت سیستم ارائه می گردد.
فرمت گزارش مفصل
گزارش مفصل مطابق ورژن چهارم استاندارد OWASP ارائه می شود و شامل موارد زیر است.
1. خلاصه مدیریتی: شامل خلاصه موارد تست شده و وضعیت هر مورد و تاثیری که اسیب پذیری ها می تواند بر روی سیستم داشته باشد.
2. پارامتر های تست: در این بخش موارد که در تست موثر بودند بیان می شود و شامل موارد زیر است:
2.1 هدف پروژه
2.2: دامنه پروژه: محدوده پروژه که در قرارداد امده است.
2.3: زمان بندی پروژه: زمان شروع و پایان پروژه.
2.4: اهداف: سیستم هایی که هدف تست بودند.
2.5: محدودیت ها: در این بخش محدودیت های دسترسی و امکانات تست بیان می شود.
2.6: جدول اسیب پذیری ها: شامل جدولی از خلاصه اسیب پذیری که در سیستم یافت شده است.
2.7: توصیه ها برای رفع: در این بخش توصیه هایی برای رفع اسیب پذیری های سیستم بیان می شود این توصیه های به صورت خلاصه است.
2.8: لیست ابزارهایی که در طی تست از انها استفاده شده است به همراه نسخه.
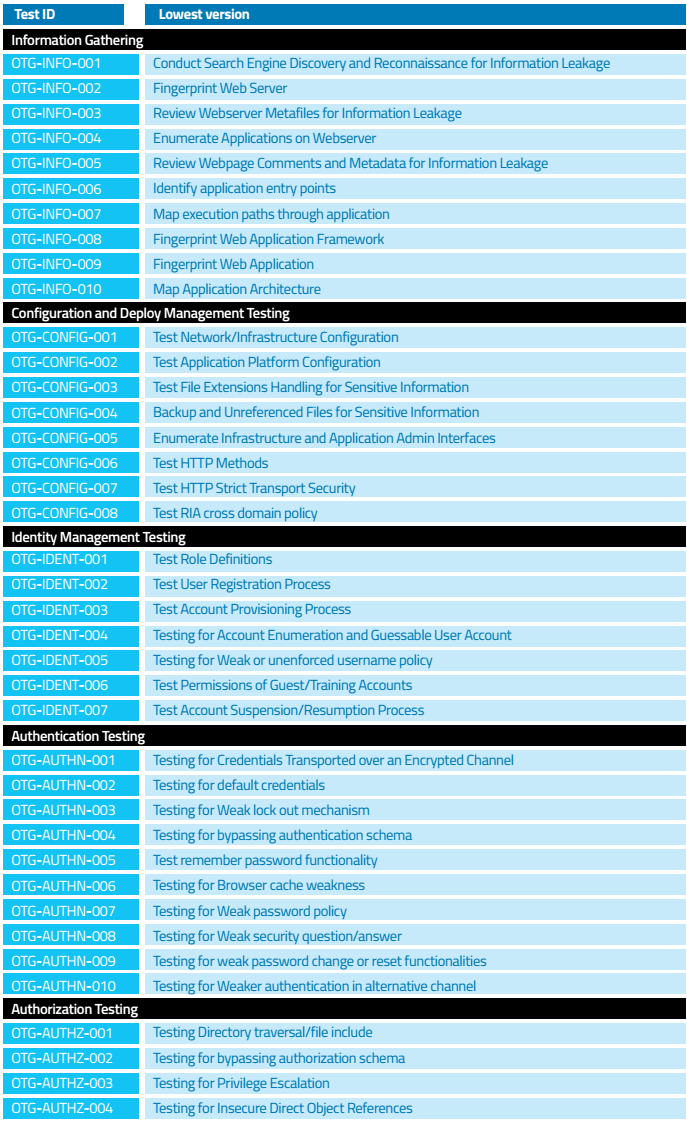
3. یافته ها: در این بخش TESTLOG ها و تست های انجام شده چه موفق و ناموفق به همراه عکس و ارجاع به فیلم ها بیان می شود. کلیه TEST CASE های استاندارد OWASP بایستی توسط سناریوهای این بخش پوشش داده شود و مشخص شود سناریو برای اجرای کدام TEST CASE بوده است. در اخر هر سناریو بایستی راه حل هایی جهت رفع انها با جزئیات کامل بیان شود. هدف هر سناریو بایستی در ابتدا بیان شود و در انتها مشخص شود که تا چه حدی این هدف محقق شده است.
در ادامه برخی از این TEST CASE ها امده است.
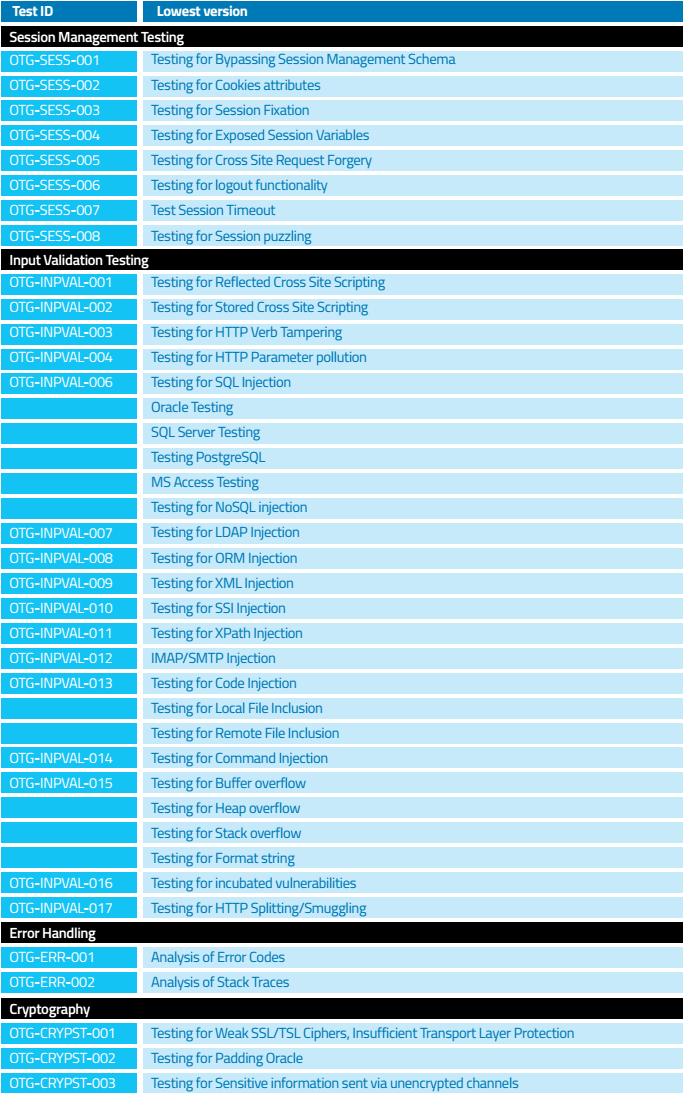

فرمت گزارش موقت
این گزارش شامل یک سناریو و یا بخشی از یک سناریو است که خلاصه ان در قالب یک ایمیل یک صفحه ای به انضمام عکس ها و فیلم ها ارائه می گردد.
در پایان هر روز از تست یکی از این گزارشات اعلام می شود.
بخش های مورد تست
در این بخش قسمت های مختلف سیستم النون بیان شده است که زمان تخمینی و هزینه ی هر تست نیز باید محاسبه گردد.|
ماژول النون |
زمان تخمینی |
هزینه |
|
وب APP |
|
|
|
CAS |
|
|
|
ORGMAIL.IR |
|
|
|
SUPPORT |
|
|
|
پنل پیامک |
|
|
|
انجین پیامک |
|
|
|
ZCP |
|
|
|
ذکرانه |
|
|
|
APP بازی |
|
|
|
بلاگ |
|
|
|
پلاگین اخبار |
|
|
|
پلاگین قرانی |
|
|
|
مسابقه |
|
|
|
وب سرویس ایمیل |
|
|
|
GATEWAY(IMAP،POP3) |
|
|
|
NETWORK (معماری و اسیب پذیری) |
|
|
|
WEBAPP سازمانی |
|
|
|
درایو |
|
|
|
Elenote بلاگ النون |
|
|
|
App email |
|
|
|
بازمون |
|
|
سیستم النون از بخش های زیر تشکیل شده است. برای هر قسمت اسیب پذیری هایی که تا کنون یافت شده اشاره شده است و همچنین راه حل برای هر قسمت نیز بیان گردیده است.
|
آسیب پذیری |
ماژول درگیر |
علت |
راه حل |
|
بدون کلمه عبور بودن zcp از ماشین webapp |
ZCP |
راه اندازی sso با کمترین تغییرات در zcp |
اعمال استفاده از ticket در کد zcp |
|
اسیب پذیری xss در وب app |
webapp |
مشکل html encode نکردن در برخی قسمت ها |
تغییر در کد Webapp و به روز رسانی jquery |
|
مشکل misconfiguration در apache |
appache |
تنظیمات مربوط به apache |
هاردنینگ apache ها |
|
یکسان بودن کلمات عبور |
شبکه |
عدم انجام صحیح تنظیمت |
مطابق سیاست های کلمه عبور انجام شود |
|
Sql injection در ارتباط با پایگاه داده |
Webapp |
کدهایی که ما اضافه کردیم در ارتباط با پایگاه داده sqlinjection رعایت نشده است |
استفاده از کوئری های پارامتری با استفاده از PDO در php |
|
آسیب پذیری dos در سرویس های وب |
تمامی سرویس های وب |
بایستی از captcha در ورود استفاده شود |
استفاده از WAF و captcha در سیستم |
|
ارسال تعداد نامحدود ایمیل و از کار انداختن سرویس ایمیل |
MTA |
محدود سازی تعداد ایمیل های ارسالی و دریافتی یک کاربر بر حسب زمان و استفاده نکردن از captcha |
محدود سازی تعداد ایمیل های ارسالی و دریافتی یک کاربر بر حسب زمان و استفاده کردن از captcha |
|
امکان استخراج نام یک فرد از روی شماره موبایل در درایو |
درایو |
وجود باگ در درایو |
رفع باگ درایو |
|
مشکلات امنیتی در wordpress ها |
تمامی سایت های wordpress |
ضعف های امنیتی wordpress |
به روز رسانی مداوم wordpress ها و استفاده از WAF در حالت بلاک در ان ها |
|
مشکل وجود DSD که در اپاچی بسته شده و در صورت دیده شدن امکان دریافت فایل های همه کاربران وجود دارد |
درایو |
کار کردن پلاگین وب app بدون داشتن کلمه عبور در استفاده از cas ، imap بدون کلمه عبور استفاده شده است |
اصلاح پلاگین و استفاده صحیح از پلاگین درایو در وب اپ |
|
مشکل عدم وجود تصدیق اصالت در سرویس های سمت سرور ذکرانه |
ذکرانه |
عدم پیاده سازی تصدیق اصالت برای هر سرویس |
استفاده از تصدیق اصالت برای هر سرویس |
|
نگهداری کلمات عبور به صورت متن باز در کانفیگ ها |
تنظیمات اکثر ماژول ها |
عدم تمرکز در کانفیگ ها |
رمزنگاری و خواندن کلمات عبور از یک مرجع |
|
تغییر کلمه عبور بر روی cas تاثیر نمی گذارد و از کار نمی افتد |
cas |
وجود باگ در cas |
رفع باگ cas |
6. جلوگیری از شنود ترافیک های مبادله شده
ایجاد تعادل ببین امنیت و سهولت استفاده یکی از مشکلاتی است که در زمینه ایمیل با ان مواجه هستیم.
5.1.3 چالشهای کسب و کاری
- سلب اعتماد، علاقه و توجه مردم به خدمات دولتی و حاکمیتی
- بروکراسی شدید، کند و پیچیده برای حمایت دولت از خدمات بومی و عدم اتخاذ سیاستها و روشهای چابکتر، درستتر و با احتمال موفقیت بالاتر
- ضعف دانشی و تجربی عمده نیروهای انسانی در کشور برای حل مسائل پیچیده و زمانبر موجود در فرآیند حساس خدمتدهی رایانامه
- کمبود شدید و هزینه بالای نیروهای انسانی متخصص و با تجربه در زمینههای فنی (برنامه نویسی، شبکه، سخت افزار، معماری، پایگاه داده، امنیت و...)، مدیریتی (سطوح کلان و میانی) و بازاریابی (سطوح راهبردی و اجرایی)
- مشکلات یافتن نیروهای مدیریتی در سطوح کلان و میانی و نیز طراحان و مجریان راهبردهای بازاریابی مجرب و قوی
- هزینههای انبوه بخشهای نرمافزاری، سخت افزاری، مرکز داده، مدیریتی، بازاریابی و پشتیبانی که به صورت جاری وجود دارند و به سرعت افزایش مییابند
- چالش پیدا کردن بهترین مرکز داده در کشور که پایداری، امنیت و پشتیبانی خوب و مناسبی در حد خدمت رایانامه داشته باشد (برای این منظور، باید بسیاری از کارهای زیرساختی شبکه را خودتان متحمل شوید تا درگیر مسائل مراکز داده داخلی نشوید؛ مثلاً برای جلوگیری از هرزنامه شدن و از بین رفتن اعتبار IPهای خدمت، باید شماره AS خود را از ابتدا تهیه کرد و...)
- لزوم صرف هزینه و زمان زیاد برای تحقیق و توسعه خدمات شبکه محتوارسان (CDN)، خدمات ابری و... (به دلیل اینکه به شکل مطلوبی در کشور وجود ندارد)
- باید ویژگیهایی در محصول وجود داشته باشد که اولاً حداقلهای مورد نیاز و انتظار عامه کاربران را در مقایسه با خدمات رقیب داشته باشد (توسعه فناوری در حد نصاب قابل عرضه به مخاطبان)، و ثانیاً ویژگیها و امکانات نوآورانه خاصی داشته باشد که کاربران را تشویق به استفاده از این خدمت کند و به خاطر این خدمات ارزش افزوده، کاربران جدید را جذب کرده و کاربران قدیمیتر را متمایل به تحمل سختی مهاجرت به خدمت موجود کرد.
- وجود انتظارات و اولویتهای متفاوت میان به دو دسته مشتریان سازمانی و عمومی محصول رایانامه:
- سازمانها و شرکتهای داخلی: سهولت استفاده از رایانامه، امنیت سرویس، صیانت از اطلاعات کسب و کاری، پشتیبانی خوب و با کیفیت مطلوب
- کاربران (عموم مردم): سهولت استفاده از رایانامه، قابل اعتماد بودن رایانامه در خصوص صیانت از اطلاعات شخصی افراد، قدرت و دقت بیشتر در ارائه خدمات مرتبط با زبان فارسی، قدرت و دقت بیشتر در ارائه خدمات مرتبط با اطلاعات کشوری و محلی، ارایه امکانات متنوع در خدمت و جذابیت هرچه بیشتر آن، پشتیبانی خوب و با کیفیت مطلوب
- چنین تفاوتهایی، باعث میشود که بعضاً در نوع معماری فنی و طراحی و پیاده سازی امکانات و ویژگیهای مورد نظر و اولویتدهی به هرکدام، تضادها و پیچیدگیهایی به وجود بیاید که ناچار باید مسیرهای متفاوتی را با توجه به شرایط موجود انتخاب کرد و میان کاربران عمومی و خوستههای آنها و کاربران سازمانی و شرکتی و دغدغههای ایشان، نهایتاً به یک سمت جهتگیری کرد.
- راهکارهای توسعه بازار، بازاریابی و درآمدزایی برای این دو دسته نیز نیاز به فعالیتها، اقدامات و تلاشهای گوناگونی دارد که شرکت را در مسیرهای جداگانهای به حرکت وادار میکند؛ بنابراین، نیاز به دو یا چند برابر کردن نیروی انسانی، هزینه و غیره در این راههاست (مثلاً مسأله شایع جا نیافتادن خدمتگیری به صورت ابری از خدمات دهنده است که بهویژه در سازمانهای دولتی، سنتی و بزرگ به شکل گستردهای دیده میشود).
- لزوم صرف وقت و هزینه فراوانی باید برای تغییر عقاید غلط به جای مانده از چارچوبهای گذشته (گرچه متأسفانه در بسیاری از موارد این محافظهکاری نهادینه شده به راحتی زدوده نمیشود که هزینهها و دردسرهای فراوانی در ارائه و پشتیبانی خدمت را به دنبال میآورد)
- ضرورت باز بودن بستر و تعامل داشتن با همه دیگر خدمات دهندگان کوچک و بزرگ (علاوه بر ادامه توسعه مداوم فناورانه و افزودن ویژگیها و قابلیتهای جدید)، چراکه بار ارائه خدمات جانبی و ارزش افزوده متنوع را از روی فراهم کننده بستر بر میدارد و میتواند پاسخگوی انواع نیازهای جدید کاربران گوناگون باشد.
- هیچگاه نباید خطر ورود فناوریهای دگرگونکننده جدید را فراموش کرد و این رقبا را دست کم گرفت (برای نمونه، اکنون پیامرسانها نحوه تولید، توزیع و مصرف اطلاعات را بهویژه برای کاربران عمومی متحول کردهاند و دیگر رایانامه آن جایگاه سابق را برای دریافت و ارسال اطلاعات ندارد).
- باید همواره خود را با شرایط و فناوریهای روز تطبیق داده و بهموقع به تحقیق و توسعه و روزآمد کردن خدمات پرداخت، تا از این گردونه رقابت شدید و روزافزون خارجی و داخلی، به ناگاه بیرون انداخته نشویم.
همچنین در بخش ۴.۴ با عنوان «ملاحظات کسب و کاری لازم برای پیاده سازی یک خدمت رایانامه عمومی (با کاربران بالا)» به طور مفصلتری به این مسائل و نکات دیگری (بهویژه برای شرکتهای نوپا) پرداخته شده است.
[2] Open Source SIEM & Open Threat Exchange Projects
اگر قبلا در بیان ثبت نام کرده اید لطفا ابتدا وارد شوید، در غیر این صورت می توانید ثبت نام کنید.